TIL_24.08.30_DL(딥러닝)
▶ 머신러닝 vs 딥러닝
● 공통점 :
- 데이터로부터 가중치를 학습하여 패턴을 인식하고 결정을 내리는
알고리즘 개발과 관련된 인공지능(AI)의 하위 분야
● 차이점 :
- 머신러닝 : 데이터 안의 통계적 관계를 찾아내며 예측이나 분류를 하는 방법
- 딥러닝 : 머신러닝의 한 분야로 신경세포 구조를 모방한 인공신경망을 사용
▶ 딥러닝의 유래
● 인공 신경망(Artifical Neural Networks)
- 인간의 신경세포를 모방하여 만든 망(Networks)
1) 단층 신경망 : 입력층과 출력층으로 구성(단일 퍼셉트론)
2) 다층 신경망 : 입력층과 출력층 사이에 1개 이상의 은닉층 보유
(다층 퍼셉트론)
- 은닉층 수는 사용자가 직접 정
● 신경세포
- 이전 신경세포로 들어오는 자극 이후 ,
신경세포로 전기 신호로 전달하는 기능을 하는 세포
● 퍼셉트론(Perceptron) : 인공 신경망의 가장 작은 단위
▶ 가중치를 구해라 - Gradient Descent
● 회귀 문제에서 최소화 하려는 값
- Mean Squared Error(MSE) : 에러를 제곱한 총합의 평균
- 즉, 가중치 (weight)를 이리 저리 움직이면서 최소의 MSE를 도출해내면 된다.

● 경사 하강법(Gradient Descent)
- 모델의 손실 함수를 최소화하기 위해 모델의 가중치를 반복적으로
조정하는 최적화 알고리즘
- 변수 X가 여러 개 있다면 동시에 여러 개의 값을 조정하면서
최소의 값을 찾으면 된다.
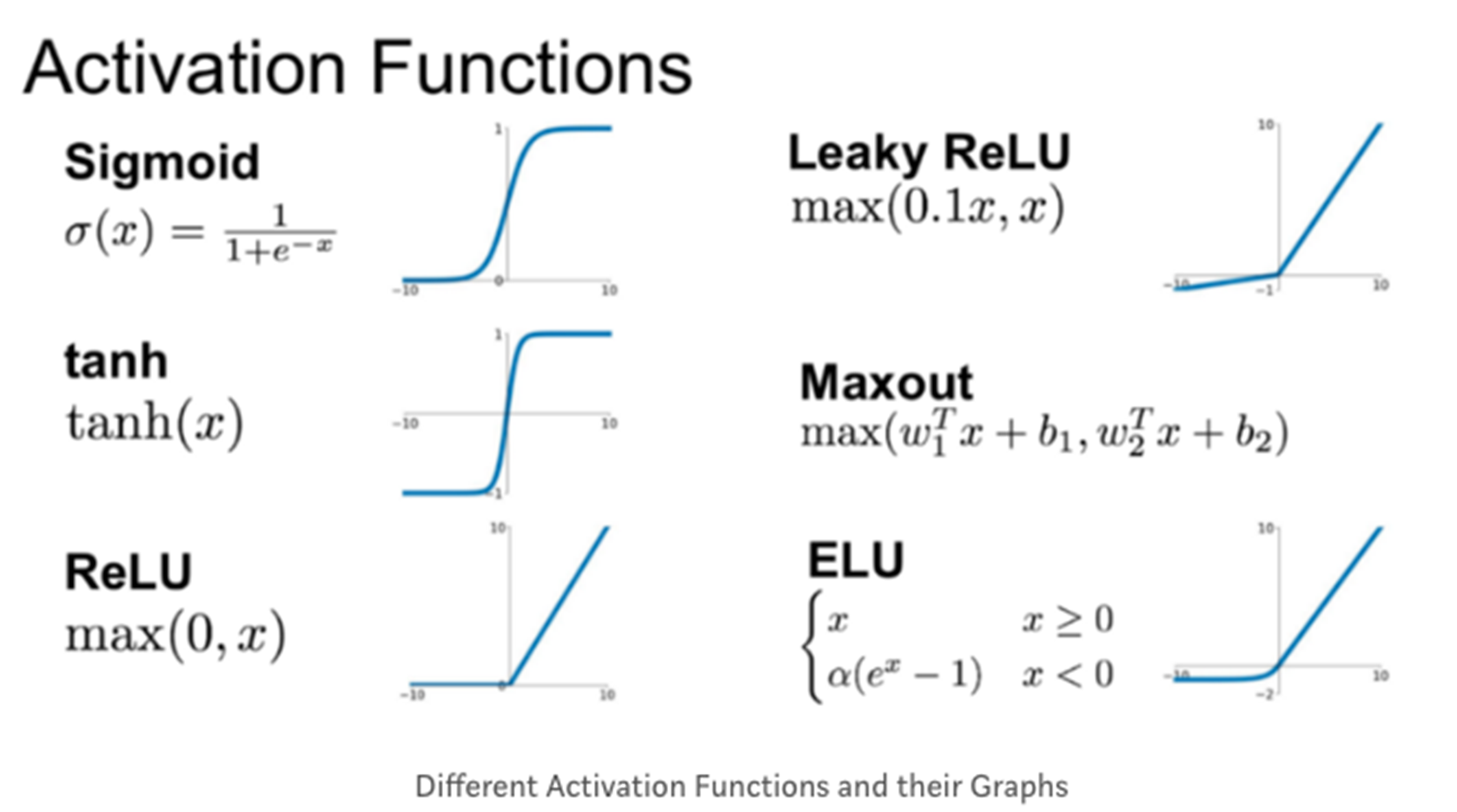
▶ 활성화 함수의 등장
- 타이타닉 문제에서 사망, 생존과 같은 비선형적 분류를 만들기 위해
활성화 함수(Activation Function)을 사용
- 로지스틱 회귀 때 배웠던 로지스틱 함수(시그모이드 함수의 한 예)
역시 활성화 함수의 한 예
▶ 히든 레이어(은닉층)의 등장
- 데이터를 비선형적으로 변환함과 동시에 데이터의 고차원적 특성(ex. 이미지, 자연어)을
학습하기 위해 중간에 입력과 결과 외의 추가하게 되는 히든 레이어의 개념 등장

- 히든 레이어를 추가할수록 좋은 모델이 나오는 것이 아니라 실제로는
기울기 소실문제가 발생
● 인공 신경망의 학습
- 입력 데이터가 신경망의 각 층을 통과하면서 최종 출력까지
생성되는 과정을 순전파(Propagation)
- 신경망의 오류를 역방향으로 전파하여 각 층의 가중치를
조절하는 과정을 역전파(Backpropagation)
● 기울기 소실 문제 등장
- 문제 : 역전파 과정에서 하위 레이어로 갈수록 오차의 기울기가
점점 작아져 가중치가 거의 업데이트 되지 않는 현상
- 해결 : 특정 활성화 함수(ex. Relu)를 통해 완화하게 됨
▶ epoch
● epoch : 전체 데이터가 신경망을 통과하는 한 번의 사이클
- 1000 epoch : 데이터 전체를 1000번 학습
● batch : 전체 훈련 데이터 셋을 일정한 크기의 소 그룹으로 나눈 것
● iteration : 전체 훈련 데이터 셋을 여러 개(= batch)로 나누었을 때
배치가 학습되는 횟수

ex) 1000개의 데이터 batch size 100개라면, 1 epoch에는 iteration은 10번
일어나며 가중치 업데이트도 10번 진행
▶ 딥러닝 패키지
●Tensorflow
- 구글이 오픈소스로 공개한 기계학습 라이브러리로 2.0버전부터는
딥러닝 라이브러리를 구축하는 keras패키지를 통합하게 되었다.
●Pytorch : 메타에 의해 개발됨, 토치(torch)기반의 딥러닝 라이브러리
▶ Tensorflow 패키지 이해
● tensorflow.keras.model.Sequential
○ model.add : 모델에 대한 새로운 층을 추가함
- unit
○ model.compile : 모델 구조를 컴파일하며 학습 과정을 설정
- optimizer : 최적화 방법, Gradient Descent 종류 선택
- loss : 학습 중 손실 함수 설정
- 회귀 : Mean_Squared _Error
- 분류 : categorical_ crossentropy
- metrics : 평가척도
- mse : Mean Squared Error
- acc : 정확도
- f1_score : f1 score
○ model.fit : 모델을 훈련 시키는 과정
- epochs : 전체 훈련 데이터 셋에 대해 학습을 반복하는 횟수
○ model.summary() : 모델의 구조를 요약하여 출력
● tensorflow.keras.model.Dense : 완전 연결된 층
- unit : 층에 있는 유닛의 수, 출력에 대한 차원 개수
● model.evaluate : 테스트 데이터를 사용하여 평가
● model.predict : 새로운 데이터에 대해서 예측 수행